Occam’s Razor in Software Development
Occam’s razor is one of the most powerful problem-solving principles applicable in life as well as software development. It is probably not well known and is often misunderstood and under-utilized.
In this post, I disambiguate it and enumerate multiple formulations and common misinterpretations. I will demonstrate that many principles and practices in software development are applications of Occam’s razor, and list some missed opportunities.
The premise of Occam’s razor is that “entities should not be multiplied without necessity”. It advocates that when presented with competing hypotheses about the same prediction, one should select the solution with the fewest assumptions and that this is not meant to be a way of choosing between hypotheses that make different predictions. -Ⓐ
It is often mistaken to advocate simplicity, but has a more nuanced recommendation, which is described by the quote “Everything should be made as simple as possible, but no simpler.” -Ⓑ Wikipedia has more formulations of this principle “It is vain to do with more what can be done with fewer”-Ⓒ
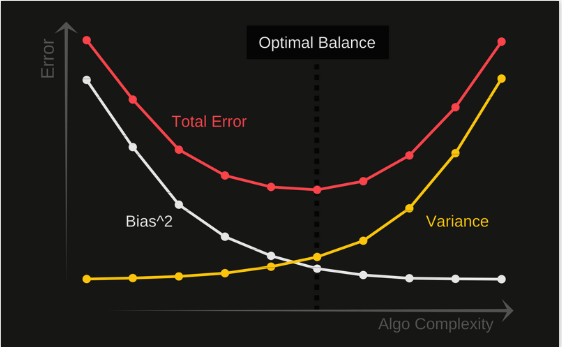
In the world of predictive models, one needs to maintain a balance between model complexity and error, that would be a sweet spot between over-generalization and over-specialization.

This leads to yet another formulation “reduce complexity, if and only if you can” -Ⓓ
Interpretation
Occam’s razor can be generalized to two-dimensional problems where we optimize in one dimension while satisfying constraints in another.

There are two different maps of the Bengaluru metro, both of which show the green line. Both of them show the ordering of stations, while the first of them captures the physical orientation as well. Is the first map conformant to Occam’s razor or is it the second? well, it depends on the problem at hand. This illustrates another observation on Occam’s razor, “it is contextual”. The best hypothesis in one context, needn’t be the best in another.
Essential vs Accidental Complexity
The philosophy of “Manage Essential complexity and reduce/eliminate Accidental Complexity” is a key application of Occam’s Razor.
Information
Information refers to anything that needs to be remembered and managed during software development. It encompasses data, config, requirements, code, and documentation.
Abstraction
One of the pillars of software engineering is abstraction and there is this great quote, “The essence of abstraction is preserving information that is relevant in a given context, and forgetting information that is irrelevant in that context.”– John V. Guttag[1].

Generalization
by application of abstraction, a general concept can be formed by extracting common features from specific examples. Reasoning can be performed at the concept level instead of the specific instance level.

Encapsulation

“Encapsulation is the grouping of related ideas into one unit, which can thereafter be referred to by a single name” — Meilir Page-Jones

Generalization by encapsulation reduces the amount of information in your code.
Inheritance
Inheritance is a mechanism of wrapping the commonality without forgetting differences. This allows clients to reason on the base class basis where possible.

Parametrization
Parameters allow programs to reason with formal parameters(like x) instead of actual parameters(like 20). Parametrization thus hides details about the clients from the server. It is a means of raising the level of abstraction and is a type of generalization increasing the expressiveness of modules.
Dependency inversion
Dependency inversion is an application of the parametrization pattern, where the inverted object can consist of family/ies of dependencies.
Higher Order Functions
Higher-order functions are another manifestation where the efficacy of methods is raised by allowing for a family of functions instead of one.
Parametric polymorphism
In programming languages and type theory, parametric polymorphism is a way to make a language more expressive, while still maintaining full static type safety. Using parametric polymorphism, a function or a data type can be written generically so that it can handle values identically without depending on their type
Higher Kinded Types
A higher-kinded type is a type that abstracts over some type that, in turn, abstracts over another type. It’s a way to generically abstract over entities that take type constructors. They allow us to write modules that can work with a wide range of objects.
Platformization

The salient features of platforms are that production and value creation happens outside of the platform. The interaction between producers and consumers is the value creation activity. Note that for the platform the producers and consumers are parameters.
Commitment
By reducing the number of assumptions that clients of modules can make, the software can support more clients/use cases.
Information Hiding
Information hiding is the principle of segregation of the design decisions in a computer program that are most likely to change, thus protecting other parts of the program from extensive modification if the design decision is changed. The protection involves providing a stable interface that protects the remainder of the program from the implementation (the details that are most likely to change).
Interface Segregation principle
Interface Segregation Principle splits interfaces that are very large into smaller and more specific ones so that clients will only have to know about the methods that are of interest to them.
Composition over inheritance
This is an application of the interface segregation principle, where a broader contract to clients of a class is avoided in favor of a narrower one.
Chunking
chunking is a process by which individual pieces of an information set are broken down and then grouped together into a meaningful whole. The chunks might not have any redundancy compared to the whole. Chunking allows humans to deal with information overload, by reasoning at the abstraction of chunks.
Essence over ceremony
Good code captures and communicates essence while omitting ceremony (irrelevant detail). The ceremonious code is not(always) eliminated, but is linked into.
Composition
Objects, functions, and methods can be composed to form other constructs of the same type.
Connascence
Connascence is a measure that quantifies the need to change a component because of a change in another. It is a property of information that we will reason independently.
Loose Coupling
Loose coupling is achieved by reducing the number of other components, a component is connascent with.
High Cohesion
By encapsulating a group of connascent components into a bigger component, we are isolating the need to change and containing information overload.
Type 1 and Type 2 errors
In Ⓐ, when presented with multiple hypotheses for an observation, amongst those which have passed the test for correctness choose the one, which makes the fewest assumptions i.e there are two different criteria for choosing solutions 1) correctness and 2)magnitude.

In the context of the above diagram, h₃ is the best solution, even if h₁ makes fewer assumptions
Decision-making can make mistakes on both fronts. The following memes capture two kinds of errors, depicting perils of over-emphasis on single criteria

Errors in hypothesis selection can be categorized into two types.
- where an incorrect hypothesis is chosen
- where an inefficient hypothesis is chosen
Opportunities
The mainstream view of software developments has practices that are errors when viewed from the lens of Occam’s razor. The errors are categorized as Type1 or Type2 below.
Type 1
Boxes and Arrows
Years ago, in an interview, a candidate was asked to describe the architecture of the system he had worked on. He drew a picture of a box, an incoming arrow, and an outgoing arrow. He labeled the box as a system, the incoming arrow as input, and the outgoing arrow as output. This model of the system is useless. The practice of using Boxes and Arrows to describe the architecture isn’t much better than the one mentioned earlier. It conveys too little and hence opens up lots of ambiguities and unanswered questions.
Anemic Domain Model
Check the implementation of Stack. While the implementation is simpler stack displays LIFO behavior only if mutations are performed via the push and pop methods. If the stack is accessed directly, the LIFO invariants can be violated negating the contracts.
This kind of weak information hiding is the basis of the Anemic Domain Model anti-pattern which unfortunately is quite prevalent.
Bad Names
If the method were to receive an invalid argument, should it raise an “ArgumentException” or “InvalidArgument”? common sense tells us it is InvalidArgument, but this isn’t followed at least in the Java world, find below a few such examples.

Type 2
Code as (the only) model
The other extreme of the Boxes and Arrows model is code as the model. Code is a means of communicating with machines, it captures too much low-level information to be useful as the only model or reasoning.
Long names
The picture below should suffice for the verbosity of modern programmers.

Unwarranted Agglutination
Words are glued together to make bigger words even when unnecessary. The left column of the table below enumerates such mistakes, while the right lists their better versions.

P.S the pictures used are from google searches and from a slide deck from Kevlin Henney

{kind=link}